

Most companies run assessments backwards. They measure what's easy to measure instead of what actually matters for job performance.
A regional healthcare network scrapped their entire assessment library after discovering their 45-minute competency tests had zero correlation with actual nurse performance ratings after 12 months. Their highest scorers on clinical knowledge assessments were averaging 2.8 out of 5 on performance reviews. Meanwhile, nurses who barely passed were getting 4.2 ratings and getting promoted within 18 months.
The problem runs deeper than bad test design. Traditional assessments measure the wrong things at the wrong time using the wrong methods. They capture test-taking ability, not job capability. Knowledge recall, not skill application. Controlled responses, not realistic behaviors.
Why traditional competency assessments fail
Assessment failure starts with a fundamental mismatch between what gets measured and what matters on the job.
Take technical support roles. Companies love testing product knowledge and troubleshooting frameworks. Candidates memorize documentation and ace the exam. Then they freeze when facing an angry customer who needs help right now while their toddler screams in the background and their internet keeps cutting out.
The assessment measured theoretical knowledge. The job requires emotional regulation, rapid prioritization, and clear communication under pressure. No overlap whatsoever.
This disconnect happens because assessment design follows the path of least resistance. HR pulls generic competency models. Subject matter experts suggest testing their favorite topics. Vendors push off-the-shelf solutions. Nobody asks the basic question: what specific behaviors separate top performers from everyone else in this role, at this company?
Even when companies try measuring behaviors, they default to self-reported personality inventories or situational judgment tests. Candidates select what sounds best, not what they'd actually do. The introvert marks "I enjoy collaborating with large groups" because that's obviously the right answer for a team lead position. The conflict-avoider chooses "I address performance issues immediately" because who would admit otherwise?
Observable behavior blueprints that work
Effective micro-assessments focus on behaviors you can actually observe during the assessment itself — not what people claim they would do.
Stop losing track of critical skills.
Talioly helps you track, develop, and certify your workforce efficiently.
- Centralized skill profiles
- Automated training reminders
- Competency gap analysis
No credit card required
A logistics company struggling with dispatcher turnover rebuilt their assessment around observable stress responses. Instead of asking "How do you handle multiple priorities?" they built a 15-minute simulation. Candidates receive escalating delivery problems through a mock dispatch system. Routes fail. Drivers call with emergencies. Customers complain about delays.
-
Time to acknowledge each new issue (under 30 seconds = green)
-
Communication clarity in responses (uses specific next steps vs. vague promises)
-
Escalation decisions (recognizes when to loop in support)
-
Information organization (takes notes vs. trying to remember everything)
These behaviors directly predict success because they mirror what dispatchers actually do for eight hours every day. No theory. No self-reporting. Just observable actions under realistic conditions.
Building your observable behavior inventory
Start by shadowing your top performers for full shifts. Not interviews. Not surveys. Actual observation.
-
How they open difficult conversations
-
When they ask for clarification vs. make assumptions
-
How they organize information while multitasking
-
What they do when systems fail
-
How they transition between different types of tasks
Then shadow average and struggling performers. Note the behavioral differences. Top salespeople don't just "build rapport" — they mirror customer energy levels within the first minute or so. Average ones launch into their standard pitch regardless of customer mood.
Your assessment blueprint should capture these specific, observable differences.
A simple workflow for designing and validating observable behavior micro-assessments:
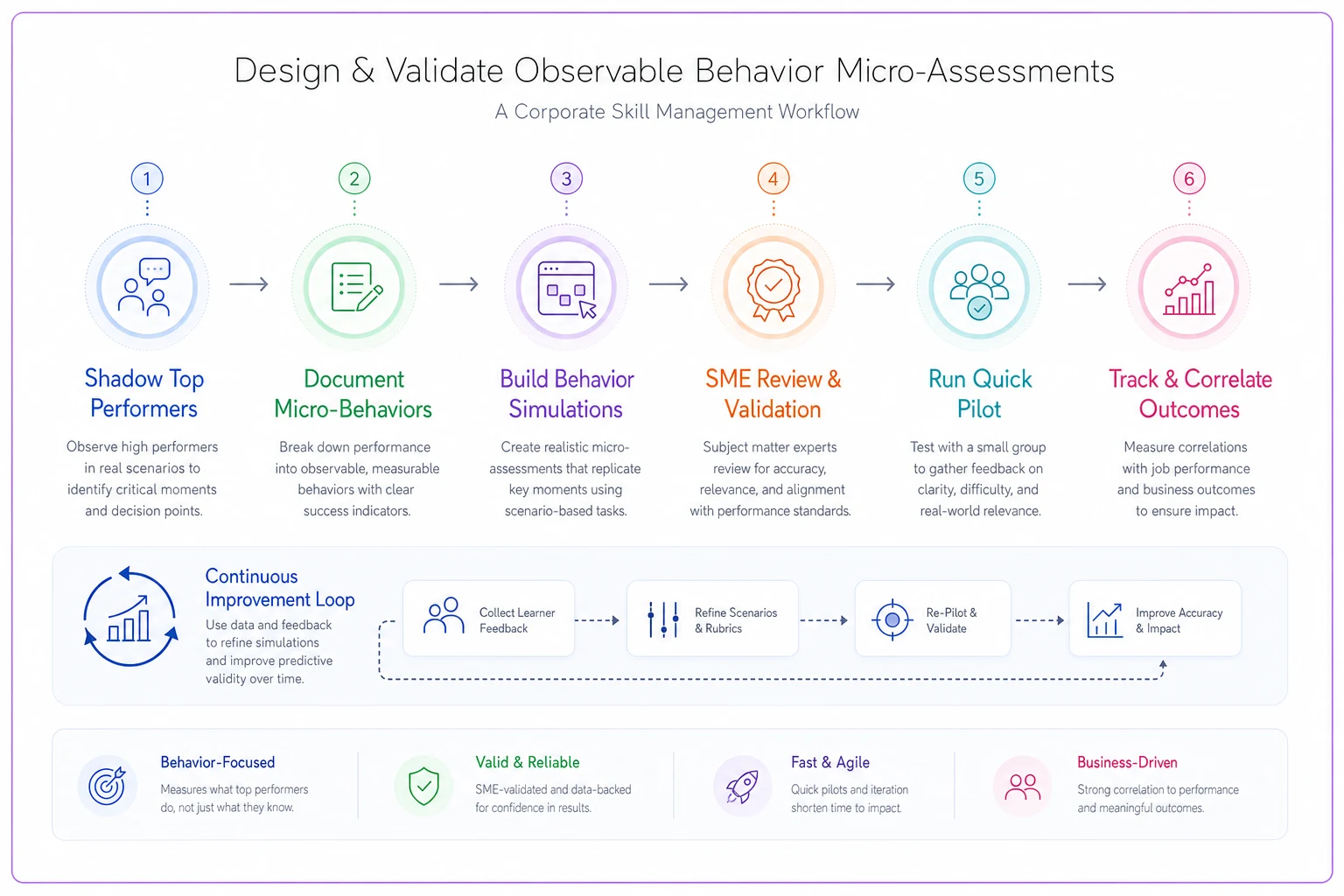
The visual shows the flow from observation to simulation to SME review to pilot testing and ongoing tracking.
SME validation without the bottleneck
Subject matter expert input is still crucial, but the traditional SME review process kills assessment development. One expert goes on vacation. Another disagrees with the rating scale. Six months pass. The role requirements change. You're back to square one.
The fix: structured SME validation with clear boundaries and fallback options.
-
3-5 specific behaviors to validate
-
Video examples of each behavior
-
Binary decision
Critical for role? Yes/No
-
Optional
Frequency rating (Daily/Weekly/Monthly/Rare)
Set a 72-hour response window. No response means validation passes to a backup SME or defaults to empirical data from job analysis. This prevents single points of failure while maintaining quality control.
Assign backup SMEs and automate the 72-hour escalation to avoid stalled validation reviews.
For scoring rubrics, use behavioral anchors instead of subjective quality ratings. Rather than "Excellent/Good/Fair/Poor" communication, define observable markers:
-
Restates the problem before offering solutions
-
Uses specific examples rather than general statements
-
Asks clarifying questions when requirements seem conflicting
-
Summarizes next steps with a timeline at conversation end
SMEs validate these behavioral anchors against actual job requirements, not idealized competency models.
Quick validation experiments before full rollout
Never launch assessments without predictive validation, but full criterion validity studies take months and hundreds of candidates. Run quick experiments first to catch obvious failures.
The 10-10-10 pilot method
Select 10 high performers, 10 solid performers, and 10 struggling performers from current employees. Run them through your assessment blind — scorers don't know who's who.
If your assessment can't distinguish between these known groups, it won't predict future performance. A customer service assessment that gives equal scores to your best and worst agents has zero predictive validity, regardless of how thorough it looks.
This quick pilot catches fundamental flaws before you waste time on full validation. One retail chain discovered their inventory management assessment actually scored detail-oriented slow workers higher than efficient multi-taskers. The behaviors they measured (double-checking counts, following every procedure) didn't align with actual performance (processing volume while maintaining acceptable accuracy).
Shadow scoring validation
Have new hires complete your assessment during onboarding. Don't use the scores for decisions — just collect the data. Track their actual performance over 90 days. Compare assessment predictions to manager ratings, quality scores, or productivity metrics.
This shadow period gives you real predictive data without risk. You'll quickly see which assessment components correlate with performance and which just add noise. One call center found their empathy assessment module had a negative correlation with actual customer satisfaction scores. High empathy scorers spent too long commiserating instead of solving problems.
Behavioral frequency alignment
Track how often assessed behaviors actually occur on the job. An assessment that heavily weights behaviors happening once a month wastes time and misses daily performance drivers.
Run simple behavior tracking for one week with a handful of employees. Every hour, they mark which assessed competencies they've used. Most roles show clear patterns — the bulk of performance comes from three or four core behavior clusters that repeat constantly. Your assessment should reflect that, not some idealized competency framework.
Scoring rubrics that reflect reality
Traditional scoring treats all competencies equally. In reality, certain behaviors matter far more than others depending on the role.
A financial services firm analyzed two years of performance data across roughly 400 employees. They found that accuracy behaviors predicted success for junior analysts but became largely irrelevant at the senior level. Senior analyst performance correlated with stakeholder management and priority juggling, not calculation precision.
Junior Analyst Scoring:
| Role | Behavior 1 | Behavior 2 | Behavior 3 |
|---|---|---|---|
| Junior Analyst | Accuracy behaviors: 50% weight | Speed behaviors: 30% weight | Communication behaviors: 20% weight |
| Senior Analyst | Priority management: 40% weight | Stakeholder communication: 40% weight | Technical accuracy: 20% weight |
This role-specific weighting improved predictive validity from r=0.31 to r=0.67 in pilot testing.
Build different rubrics for different role stages. Early career success requires different behaviors than sustained high performance. Your assessment should reflect these evolving requirements.
Common predictive validity failures
Measuring maximum performance instead of typical performance
When people know they're being assessed, they perform at their peak. But jobs require sustained typical performance, not brief bursts of excellence. A programmer might solve complex algorithms during a timed assessment then spend weeks avoiding difficult refactoring tasks on the job.
Counter this by embedding assessment elements in realistic workflows. Instead of "solve this problem," create scenarios requiring multiple competing priorities. Performance drops to more typical levels when cognitive load increases.
Over-indexing on trainable skills
Many assessments heavily weight skills that companies teach during onboarding anyway. Why screen for specific software knowledge if you provide two weeks of training? Focus on harder-to-train behaviors like learning agility, feedback receptiveness, and stress management.
One tech company removed all tool-specific questions from their developer assessments and replaced them with learning scenarios — candidates receive documentation for an unfamiliar framework and must implement a basic feature. That change improved six-month retention predictions by around 40%.
Missing role-critical constraints
Lab assessments often remove the exact constraints that make jobs difficult. Customer service assessments give candidates perfect information and unlimited time. Real agents juggle incomplete data, system limitations, and strict handle time requirements.
Add realistic constraints to your assessments:
-
Time pressure that matches actual job pacing
-
Incomplete or conflicting information requiring judgment calls
-
System limitations forcing creative workarounds
-
Interruptions and context switching
These constraints reveal who can actually perform versus who can solve theoretical problems.
Building your validation tracking system
Validation isn't a one-time event. Role requirements shift. Candidate pools change. What predicted performance last year might not work today.
Set up lightweight tracking from day one:
Assessment scores database
-
Candidate ID
-
Assessment date
-
Component scores (not just total)
-
Time to complete
-
Any technical issues or anomalies
Performance tracking
-
30-day manager rating
-
90-day performance metrics
-
6-month retention
-
12-month promotion/performance review
Correlation monitoring
-
Monthly correlation calculations between assessment components and performance metrics
-
Flag any component dropping below r=0.3
-
Alert when overall predictive validity drops below r=0.5
This tracking system runs in the background, flagging when assessments need updating. No manual analysis required until problems emerge.
Most HR teams think they need complex statistical software for validation. You don't. A basic spreadsheet with correlation formulas gives you enough insight for micro-assessment optimization. The key is consistent data collection, not advanced analytics.
Who should avoid micro-assessments
Not every role benefits from behavioral micro-assessments. Some situations make them counterproductive:
Roles with extreme variation — If every day looks completely different with no repeating patterns, behavioral assessments can't capture the full range. Executive positions, creative directors, and strategy consultants fall into this category.
Positions with long feedback loops — When performance outcomes take years to measure (research scientists, enterprise sales), micro-assessments provide false confidence. You won't know if they worked until it's too late to adjust.
Heavy culture fit requirements — Some companies prioritize cultural alignment over competency. A technically perfect candidate who clashes with team dynamics fails regardless of assessment scores. Skip behavioral assessments and focus on culture screening.
Apprenticeship models — If you hire purely for potential and provide years of training, current behaviors matter less than learning capacity and motivation. Assess cognitive ability and grit, not current competencies.
The operational reality of assessment automation
Manual assessment scoring and validation creates bottlenecks that kill program effectiveness. HR spends hours reviewing recordings, calculating scores, and generating reports instead of actually improving the assessment itself.
This is where AI-powered operational software changes the picture — not by replacing human judgment, but by handling the repetitive operational tasks that get in the way of proper validation.
Automated scoring for observable behaviors works when you've defined clear behavioral markers. The system flags when candidates demonstrate specific actions, maintaining consistency across hundreds of assessments. Human reviewers focus on edge cases and quality checks rather than routine scoring.
Validation tracking becomes automatic. As performance data flows in, the system continuously calculates correlations between assessment components and job outcomes. You get alerts when predictive validity drops, not monthly reports surfacing problems from three months ago.
The real value is iteration speed. When you can test assessment variations quickly, you find what works faster. One healthcare staffing firm tested a dozen different interview question combinations over two months using automated scheduling and scoring. Manual processing would have taken a year.
AI automation also enables more flexible assessment paths. Instead of forcing every candidate through identical assessments, the system adapts based on role requirements and prior responses. Senior candidates skip basic competency checks. Technical roles get deeper technical scenarios. The assessment actually matches the job.
Moving beyond traditional assessment mindsets
The shift from traditional assessments to predictive micro-assessments means rethinking some basic assumptions about talent evaluation.
Stop treating assessments as academic tests. They're performance samples. The goal isn't measuring knowledge or personality — it's predicting specific job behaviors.
Stop chasing perfect prediction. An assessment with 0.6 predictive validity beats interviewer gut feelings at 0.2. Good enough beats theoretically perfect.
Stop assessing everything. Focus on the three or four behavior clusters that actually drive performance differences. Comprehensive assessments waste time and hurt candidate experience without improving predictions.
The companies getting this right treat assessments as operational tools, not compliance checkboxes. They iterate constantly based on performance data. They prioritize predictive validity over face validity. They measure what matters, not what's measurable.
The most practical next step is picking one critical role and running the 10-10-10 pilot with current employees. Skip the complex competency modeling. Skip the vendor assessments. Build something simple that measures observable behaviors your top performers consistently demonstrate, validate it against real performance, and adjust from there.
That's how you build micro-assessments with actual predictive validity. Everything else is just expensive testing theater.
Ready to elevate your team's skills?
Join 500+ companies using Talioly to boost skill visibility, streamline training, and drive performance growth.