

The disconnect happens every week in mid-sized companies. Engineering needs three React developers yesterday. Meanwhile, your QA automation lead who built the entire test framework in JavaScript gets rejected because their title says "QA" not "Developer." The backend engineer who spent weekends learning React and built two side projects? Never even shows up in the search results.
This broken pattern costs companies somewhere around $42,000 per mis-hire when they bring in external candidates while perfectly capable internal talent gets overlooked. Not because they lack skills, but because internal mobility skills matching relies on job titles and manager assumptions instead of verified capabilities.
The title trap destroys internal mobility before it starts
Traditional internal job matching follows a predictable failure pattern. HR posts the role. Managers scan current titles. Anyone without the exact title gets filtered out immediately. The system assumes a "Marketing Analyst" can't possibly have the SQL skills needed for a "Data Analyst" role, even though they've been writing complex queries for campaign analysis for three years.
What makes this worse is how skills get buried inside role boundaries. Your customer success manager who automated their entire workflow using Python scripts will never appear in searches for technical roles. The operations coordinator who learned Tableau to build department dashboards? Invisible when BI roles open up.
The filtering happens at multiple layers. First, the job posting system filters by current department. Then managers filter by title similarity. Finally, HR filters by years in current role. Each layer removes qualified candidates who developed adjacent skills or self-taught capabilities outside their formal responsibilities.
Most companies try fixing this with "skills databases" where employees self-report capabilities. These fail almost immediately. Employees either undersell themselves ("I only know basic Excel" when they're building complex financial models) or oversell ("Expert in project management" after running one small project). Without verification or context, these databases become wish lists rather than reliable talent maps.
Building shortlisting rules that surface hidden talent
Effective internal mobility skills matching requires three components working together: verified skill signals, availability indicators, and learning trajectory patterns. Each needs specific rules that go beyond simple keyword matching.
Stop losing track of critical skills.
Talioly helps you track, develop, and certify your workforce efficiently.
- Centralized skill profiles
- Automated training reminders
- Competency gap analysis
No credit card required
Verified skill signals beyond self-reporting
Start with evidence collection rather than declarations. Instead of asking "Do you know Python?", track actual Python usage. Pull commit history from GitHub. Check who's accessing Python environments on company machines. Review who completed Python courses with passing scores. Map who submitted Python scripts in their regular work.
Create verification tiers that reflect real capability:
Tier 1 - Active Usage: Used skill in last 30 days in production work
Tier 2 - Recent Project: Completed project using skill in last 6 months
Tier 3 - Certified Knowledge: Passed assessment or certification in last year
Tier 4 - Learning Progress: Currently enrolled in verified training with >70% completion
Weight these tiers differently in your matching logic. Someone actively using React (Tier 1) ranks higher than someone with a React certification from two years ago (Tier 3). But someone currently learning React with 85% course completion (Tier 4) might actually rank higher than someone who used it once six months ago and hasn't touched it since.
Availability indicators that reflect real constraints
Availability isn't binary. Build nuanced rules that capture actual situations rather than just asking "available yes/no":
Immediate availability (can start within 2 weeks):
-
Project ending in next 30 days
-
Currently in rotation pool
-
Role marked as transitional
-
Manager flagged as succession planning
Near-term availability (can start within 60 days):
-
Major deliverable completing soon
-
Coverage plan already in place
-
Has documented processes and handoffs
-
Team has redundancy in role
Negotiable availability (requires planning):
-
Single point of knowledge requiring transfer
-
Mid-project but replaceable with a 4–6 week overlap
-
Manages direct reports needing reassignment
Build these into matching scores rather than hard filters. Someone with perfect skills but complex availability might still rank high enough to warrant transition planning conversations.
Learning trajectory as predictor
Historical learning patterns predict future capability better than current skills alone. Track skill adjacency and progression speed to identify high-potential matches.
Map skill families to identify adjacent capabilities. Someone who learned JavaScript can likely learn TypeScript faster than someone starting from scratch. Someone who mastered Tableau can probably pick up Power BI quickly. Build these adjacency maps from actual transition data inside your organization, not generic assumptions.
Calculate learning velocity from training records. If someone went from SQL basics to writing complex stored procedures in four months, they show high technical learning velocity. Weight this when matching to roles requiring similar skill development.
Track application patterns too. Employees who immediately apply new skills to actual work problems show higher retention and deeper understanding than those who complete training but never use it. Pull usage data from system logs, project documents, and manager observations.
Matching algorithms that actually predict performance
Simple keyword matching fails because it ignores context, progression, and potential. Build matching rules that reflect how skills actually translate across roles.
Skill distance calculations
Create skill distance scores between current capabilities and role requirements. Don't just count matching keywords — weight by:
-
Skill criticality (must-have vs nice-to-have)
-
Proficiency gaps (expert to intermediate vs beginner to expert)
-
Ramp-up time based on similar past transitions
-
Support availability (mentors, documentation, existing training)
For example, matching a Python developer to a data science role:
| Skill | Match % | Distance |
|---|---|---|
| Python expertise | 100% | None |
| Statistical knowledge | 40% | Moderate — learnable |
| Domain knowledge | 20% | High — not critical day-one |
Total match score: 72% with a 3-month ramp projection. That's still a candidate worth a conversation, especially if their learning velocity is high.
Contextual weighting based on role type
Different roles need different matching logic. Technical roles might prioritize verified coding ability. Leadership roles weight team management experience higher. Customer-facing roles need communication evidence.
Build role archetypes with specific weight profiles:
| Role Type | Factor | Weight |
|---|---|---|
| Technical | Hard skills | 60% |
| Technical | Learning velocity | 25% |
| Technical | Domain knowledge | 15% |
| Leadership | People management | 40% |
| Leadership | Strategic planning | 30% |
| Leadership | Technical knowledge | 30% |
| Analytical | Tool proficiency | 35% |
| Analytical | Problem-solving examples | 35% |
| Analytical | Communication ability | 30% |
Performance prediction from past transitions
Mine your successful internal moves for patterns. Which skill combinations predicted success? Which gaps proved manageable? Which transitions failed despite high match scores?
Track transition outcomes at 30, 90, and 180 days. Correlate with initial match scores to refine weights over time. If employees with 70% technical match but high learning velocity consistently succeed, adjust your algorithms to reflect that. Build "transition risk" scores based on historical patterns too — someone moving from individual contributor to manager for the first time carries inherent risk regardless of how well they match on paper.
The operational workflow that makes matching work
Good matching rules mean nothing without operational discipline. Build workflows that consistently collect evidence, verify skills, and keep profiles current.
Weekly evidence collection
Automated evidence gathering should run weekly, not annually. Pull from:
-
Code repositories (languages used, commit frequency)
-
Document management systems (tool usage, complexity)
-
Learning platforms (courses completed, scores achieved)
-
Project management tools (skills tagged, deliverables completed)
-
Communication platforms (technical discussions, problem-solving)
This creates fresh skill signals rather than stale annual reviews. Someone who just started using Kubernetes last month shows up immediately rather than waiting until next year's skills assessment.
Run automated evidence collection during off-peak hours to minimize system load.
Manager verification checkpoints
Managers validate skill evidence monthly through lightweight confirmation. Something like:
"System shows Sarah used Python in 3 projects this month — confirm level:"
-
Beginner (following templates)
-
Intermediate (modifying code independently)
-
Advanced (designing solutions)
-
Expert (teaching others)
This takes managers five minutes monthly versus hours annually. More importantly, it captures skills while the evidence is fresh rather than trying to reconstruct a full year of work later.
Continuous profile updates
Employee profiles update automatically based on activity, not manual maintenance. When someone completes a Terraform course, their profile updates. When they deploy infrastructure using Terraform in production, the proficiency level adjusts. When colleagues start requesting their Terraform help, the expertise indicator strengthens.
Showing employees these updates monthly matters more than most people realize — something like "Your profile gained 3 new skills this month based on your work in..." Transparency here drives behavior. Employees develop skills faster when they can see their profile actually changing in real time rather than waiting for some annual review cycle.
A simple workflow to operationalize matching looks like this:
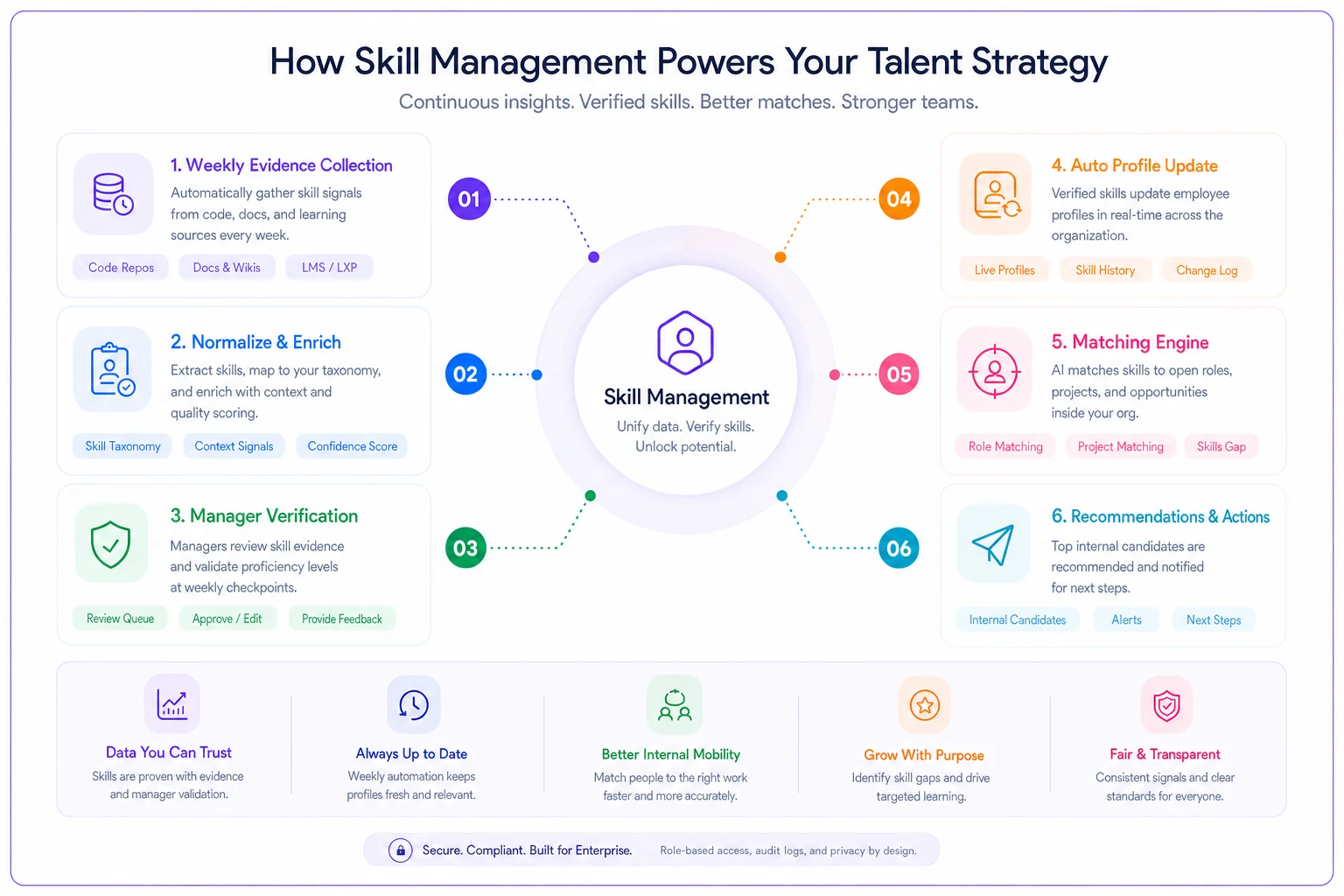
The diagram shows how evidence flows from systems into profiles, managers confirm, and the matching engine updates candidate recommendations.
Common matching failures and fixes
Even with solid rules, certain patterns consistently break matching. Recognizing them early saves a lot of frustration.
The overqualification trap
Senior employees often get filtered out for "junior" roles they'd actually want. A senior engineer might happily take an individual contributor role to escape management. A director might want to move laterally for new domain experience.
The fix is to add "role flexibility" indicators where employees mark willingness to take lateral or lower-level moves for specific reasons — new domain, work-life balance, returning to technical focus.
The hidden prerequisite problem
Job descriptions list "requirements" that aren't actually required. "5 years Python experience" might really mean "able to write production Python code." Someone with two years of intensive Python work can easily be more qualified than someone with five years of casual scripting.
Replace years-based requirements with capability-based evidence. "Has deployed Python applications handling more than 10k daily requests" beats "5+ years Python experience" every time.
The timing mismatch
Perfect candidates appear three months before roles open. By the time the role posts, they've already moved elsewhere internally or started looking outside.
Create "future opportunity pools" where employees indicate interest in role types. When a role opens, notify pool members before the general posting goes live.
Real scenario: 180-person software company transformation
A software company struggled filling technical roles while losing talent to competitors. They had 12 open engineering positions averaging 4 months to fill, while over 30 internal employees had relevant skills buried under the wrong titles.
They implemented verified skill matching over 6 months:
-
Month 1–2
Built skill evidence collection from GitHub, Jira, and learning platforms
-
Month 3–4
Created matching rules based on successful internal transfers
-
Month 5–6
Launched an internal mobility platform with automated matching
Results after 8 months:
| Metric | Before | After |
|---|---|---|
| Internal fill rate | 15% | 45% |
| Average time to fill | 120 days | 65 days |
| Failed placements | 20% | 8% |
| Estimated recruiting cost savings | — | ~$380k |
The key wasn't complex technology. They built simple rules based on evidence, not assumptions. Their QA automation lead successfully transitioned to backend development. Their technical writer became a developer advocate. Their customer success manager moved to product management. None of that would have happened with a title-based filter running the show.
Making it work with operational software
Manual skill matching breaks at scale. Spreadsheets can't track real-time skill evolution across hundreds of employees. This is where AI-powered operational software changes matching from a quarterly exercise to an ongoing process.
Modern platforms aggregate skill signals from all your systems automatically — code repositories, learning platforms, project tools, communication systems — to build living skill profiles. The automation identifies patterns that are easy to miss manually, like correlations between certain certification combinations and successful role transitions.
The practical value comes from prediction and recommendation. Instead of HR manually reviewing hundreds of profiles for each opening, the platform surfaces top candidates with match explanations. It identifies employees ready for stretch assignments. It flags situations where someone's skills have grown well beyond their current role scope.
These platforms handle the tedious tracking while HR focuses on the human side: career conversations, development planning, actual relationships. Internal candidates get fair consideration against external hires, and your best people see real growth paths inside the company instead of quietly updating their LinkedIn profiles.
Stop losing talent to title-based blindness
Internal mobility skills matching shouldn't be this hard. Yet most companies keep filtering out qualified internal candidates because their current title doesn't exactly match the open position. They'd rather spend months and significant recruiting budget going external than build simple rules to surface the talent already sitting in the building.
The fix doesn't require a major overhaul. Start with evidence collection from systems you already have. Build basic matching rules that look beyond titles. Create workflows that keep skill profiles current. Test and refine based on actual placement outcomes.
The companies getting this right aren't using more sophisticated technology than everyone else — they're using more thoughtful rules. They recognize that the customer success rep who taught themselves SQL might be their next data analyst. The QA engineer who automated their entire test suite might be their next DevOps hire.
Your employees are already developing new skills. They're taking courses, building things, solving problems that sit completely outside their job descriptions. The question is whether your internal mobility system can actually see it. Build matching rules that recognize reality: skills matter more than titles, evidence beats assertions, and potential often outweighs current capability.
The alternative is watching your best people leave for companies that recognize what they can actually do — not just what their title says they should do.
Ready to elevate your team's skills?
Join 500+ companies using Talioly to boost skill visibility, streamline training, and drive performance growth.